
Qwen 2.5: Tudo o que você precisa saber sobre o novo modelo da Alibaba
![]()
Em setembro de 2024, a empresa Alibaba lançou o Qwen 2.5, uma nova família de modelos de linguagem de larga escala que inclui versões de diferentes tamanhos, variando de 0,5B a 72B parâmetros. Além dos modelos padrão, a empresa também disponibilizou variantes acessíveis via API, como o Qwen Plus e o Qwen Turbo, e versões especializadas para aplicações específicas, como o Qwen 2.5-Coder e o Qwen 2.5-Coder-Instruct, voltados para tarefas de programação, e o Qwen 2.5-Math e Qwen 2.5-Math-Instruct, focados em problemas matemáticos complexos. A maioria dos modelos está disponível gratuitamente para uso comercial sob a licença Apache 2.0, com exceção das versões de 3B e 72B, que exigem acordos específicos para fins comerciais.
Como o Qwen 2.5 foi treinado
A família Qwen 2.5 inclui modelos de diversos tamanhos, variando de 500 milhões a 72 bilhões de parâmetros. Todos foram pré-treinados em um vasto conjunto de 18 trilhões de tokens, permitindo alta capacidade de compreensão e geração de linguagem natural. Modelos de até 3 bilhões de parâmetros podem lidar com entradas de até 32.000 tokens, enquanto os modelos maiores processam até 128.000 tokens, com uma saída de até 8.000 tokens em todas as versões.
O Qwen 2.5-Coder foi especialmente pré-treinado em 5,5 trilhões de tokens de código e está disponível nas versões de 1,5B e 7B. Esse modelo atende até 128.000 tokens de entrada e gera saídas de até 2.000 tokens, sendo otimizado para tarefas de programação.
Para problemas matemáticos, a variante Qwen 2.5-Math foi treinada em um conjunto de 1 trilhão de tokens, incluindo uma vasta gama de problemas matemáticos chineses obtidos na web e gerados pelo modelo anterior, Qwen 2-Math-72B-Instruct. Essa versão pode processar entradas de até 4.000 tokens e gerar saídas de até 2.000 tokens, disponíveis nas versões 1,5B, 7B e 72B. Além da resolução de problemas, o Qwen 2.5-Math também é capaz de gerar código auxiliar para auxiliar na solução de cálculos complexos.
Desempenho e Comparações
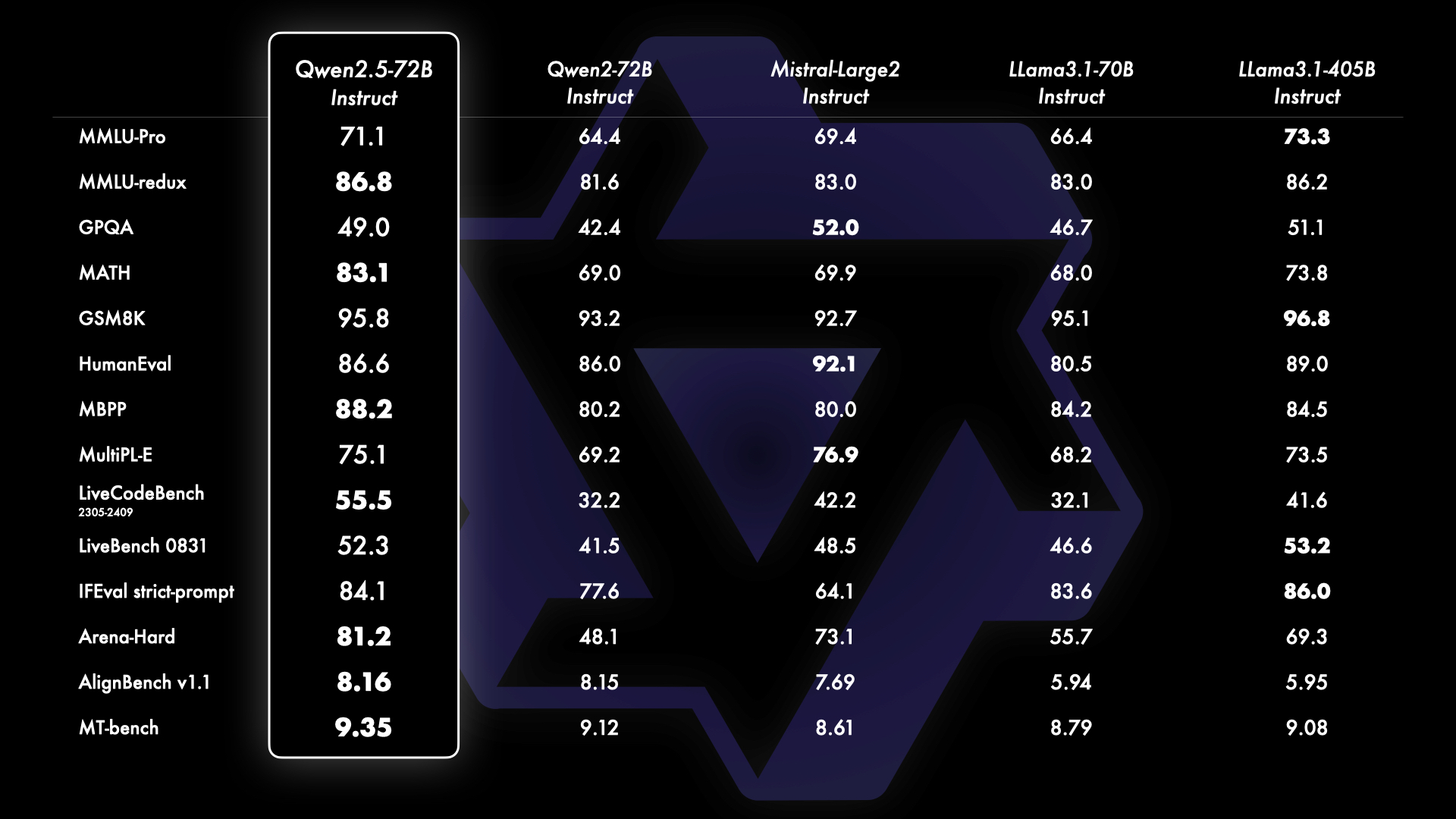
O Qwen 2.5-72B-Instruct apresenta resultados superiores em relação a outros modelos Open-Source. Em comparação com o LLama 3.1 405B Instruct e o Mistral Large 2 Instruct (123 bilhões de parâmetros), o Qwen lidera em sete dos 14 benchmarks, destacando-se no LiveCodeBench, MATH (resolução de problemas matemáticos) e MMLU (respostas a perguntas sobre diversos temas).
Entre os modelos que respondem a chamadas de API, o Qwen-Plus também se sobressai, superando o LLama 3.1 405B, Claude 3.5 Sonnet e GPT-4o em testes de MATH, LiveCodeBench e ArenaHard.
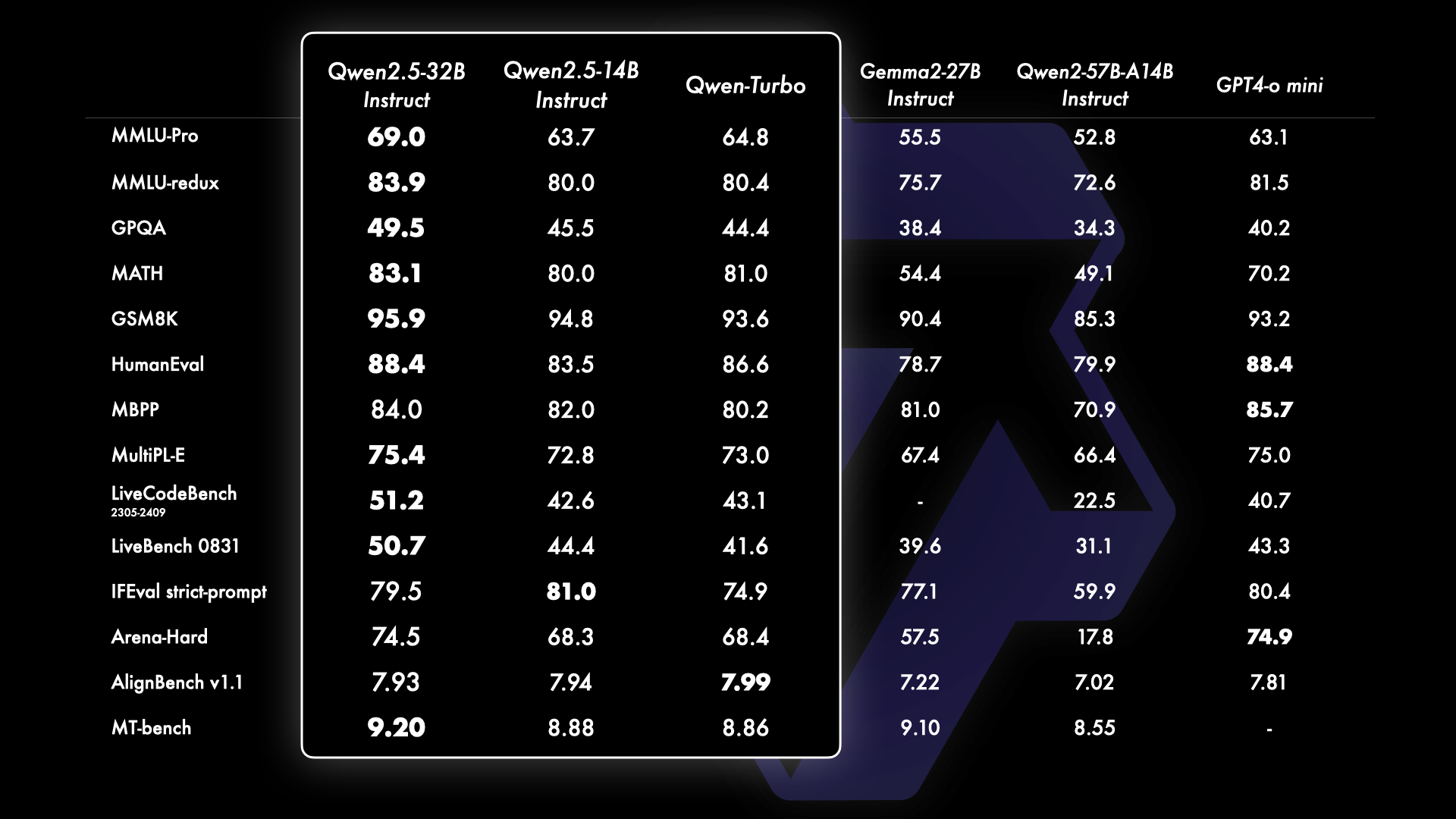
Além disso, versões menores do modelo mantêm um desempenho competitivo. O Qwen 2.5-14B-Instruct, por exemplo, supera o Gemma 2 27B Instruct e o GPT-4o mini em sete benchmarks, demonstrando a eficácia da série Qwen em diferentes escalas.
Considerações sobre a notícia
O lançamento do Qwen 2.5 representa um passo significativo na evolução dos LLMs, tornande-se um boa alteratica aos concorrentes Claude 3.5 Sonnet, GPT-4o e LLama 3.1 em , além das versões anteriores da linha Qwen 2. Mais do que apenas expandir as opções de modelos Open Source de alto desempenho, o Qwen 2.5 oferece uma alternativa competitiva frente a modelos proprietários, ideal para quem busca equilibrar alto desempenho com acessibilidade de custos.
Essa abordagem se destaca em um cenário onde muitas empresas restringem o uso de seus LLMs com licenças limitadas ou barreiras comerciais. A opção da família Qwen em manter a maioria dos modelos abertos promove um ambiente de desenvolvimento inclusivo e acessível, possibilitando que desenvolvedores e empresas explorem os recursos dos LLMs sem restrições excessivas e com maior liberdade para inovar.
Comments